
Keuntungan Menggunakan Free Spins di “Saiyan Mania”
Keuntungan Menggunakan Free Spins : Free...

Fitur Unggulan dalam slot ‘Saiyan Mania’: Apa Keistimewaannya?
Fitur Unggulan dalam slot : Game...

“Kombinasi Simbol Terbaik untuk Jackpot Besar di Saiyan Mania”
Kombinasi Simbol Jackpot Terbaik : Slot...

Panduan Cara Bermain Slot Gacor Saiyan Mania untuk Pemula
Panduan Cara Bermain Slot :Slot online...

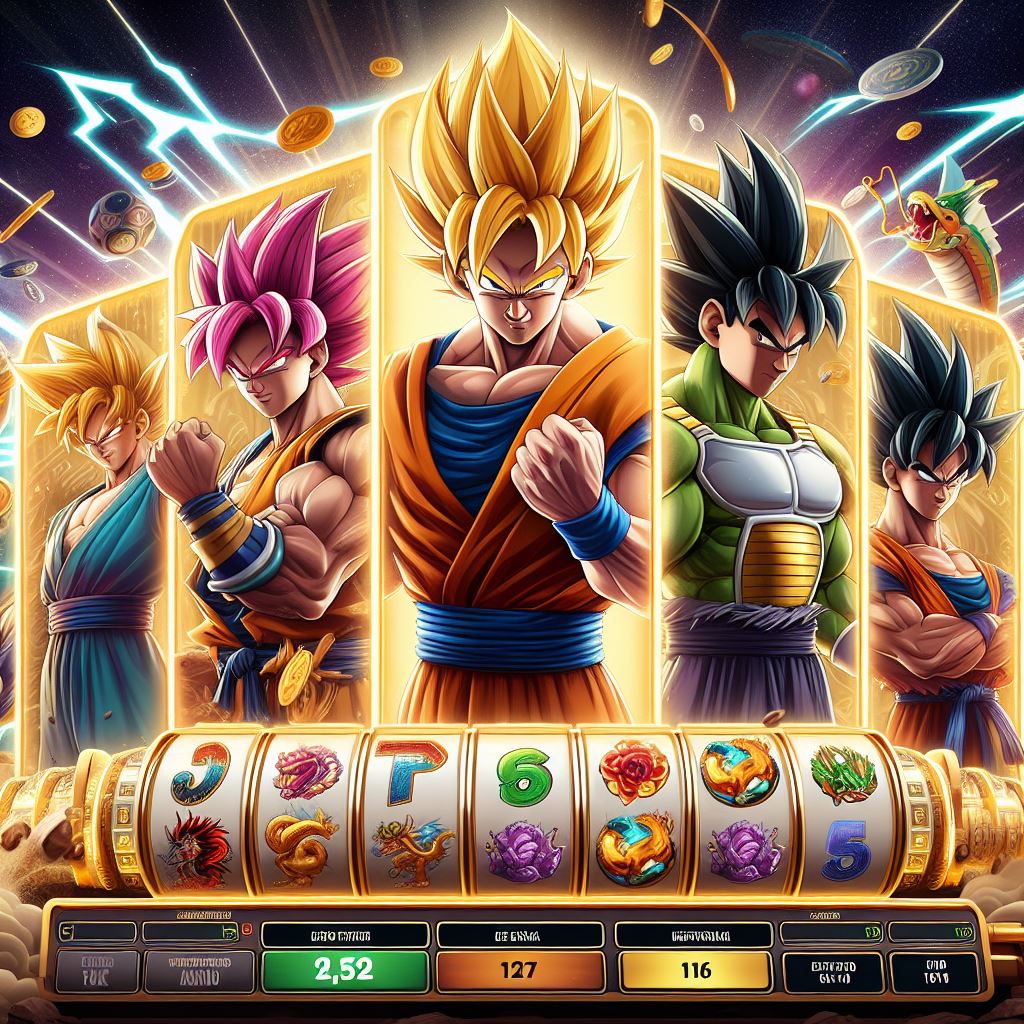
Memperkenalkan Game Slot Saiyan Mania dari Pragmatic Play
Dalam jagat permainan slot online, kebaruan...
Kisah Sukses Pemain Slot ‘Wisdom of Athena’: Inspirasi Motivasi
Kisah Sukses Pemain Slot : Dalam...

Fitur-Fitur Kunci untuk Kemenangan di Slot Wisdom of Athena
Fitur Kunci untuk Kemenangan : Slot...

Panduan untuk Pemula Slot ‘Wisdom of Athena’: Strategi & Tips
Panduan untuk Pemula Slot “Wisdom of...

Ulasan tentang Game Slot ‘Wisdom of Athena dari’ Pragmatic Play
Dalam dunia yang penuh dengan permainan...